El Ministerio de Fomento publica hoy en su página web (
observatoriotransporte.fomento.gob.es/estudio-experimental) los resultados del estudio piloto y experimental denominado “Estudio de la Movilidad Interprovincial de Viajeros aplicando la Tecnología Big Data”, como un contenido relevante dentro de los disponibles en el Observatorio del Transporte y la Logística en España. Se trata de un proyecto desarrollado durante 2018 que emplea por primera vez esta tecnología para obtener los flujos de movilidad interprovincial a nivel nacional.


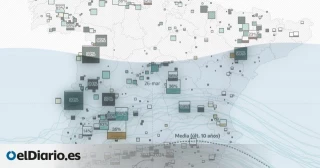


O eso, o no se entiende que nadie vaya por la ruta de la plata entre Galicia y Andalucía
#8 sólo la recopilación de datos en tiempo real tiene una infraestructura y tecnología detrás de la leche. La limpieza, transformación, agregación y anonimización tampoco se quedtiene otro tanto. a atrás. El análisis, depende de cómo les hayan pasado los datos de desagregados puede ser fácil o tener bastante complicación.
Tampoco implica "optimizaciones de bases de datos", de hecho la mayoria de veces se usan formatos planos (estilo csv) y metadatos para definir las columnas (usando Hive por ejemplo). Estos ficheros suelen estar organizados en directorios por fecha, a modo particionamiento. Lo importante es que todo se basa en un sistema de ficheros distribuido y redundante (HDFS en el caso de Hadoop, S3 en el caso de AWS,...).
Las transformaciones, muy complejas no suelen ser. Normalmente rellenar datos por defecto, traducir valores de un formato a otro. En los casos más complicados puedes tirar de herramiemtas mas complejas (ETL estilo Pentaho).
Decir hoy dia bigdata es demasiado generico. El ecosistema de Hadoop por ejemplo es inmenso, y abarca soluciones de machine learning (Spark),...